
(T) Sometimes, someone discovers that two different algorithms might be twins or at least express similar behaviors. Here is my list of a few papers that are fun to read on that topics. Please note that this list is not exhaustive.
“Transformer networks implement standard learning algorithms that closely match the predictors computed by gradient descent, ridge regression, and exact least-squares regression”, Ekin Akyürek et Al., November 2022
“Neural sequence models, especially transformers, exhibit a remarkable capacity for in-context learning. They can construct new predictors from sequences of labeled examples (x,f(x)) presented in the input without further parameter updates. We investigate the hypothesis that transformer-based in-context learners implement standard learning algorithms implicitly, by encoding smaller models in their activations, and updating these implicit models as new examples appear in the context. Using linear regression as a prototypical problem, we offer three sources of evidence for this hypothesis. First, we prove by construction that transformers can implement learning algorithms for linear models based on gradient descent and closed-form ridge regression. Second, we show that trained in-context learners closely match the predictors computed by gradient descent, ridge regression, and exact least-squares regression, transitioning between different predictors as transformer depth and dataset noise vary, and converging to Bayesian estimators for large widths and depths. Third, we present preliminary evidence that in-context learners share algorithmic features with these predictors: learners’ late layers non-linearly encode weight vectors and moment matrices. These results suggest that in-context learning is understandable in algorithmic terms, and that (at least in the linear case) learners may rediscover standard estimation algorithms. Code and reference implementations are released at this https URL.“
“Neural Networks are decision trees”, Çağlar Aytekin, October 2022
“In this manuscript, we show that any neural network with any activation function can be represented as a decision tree. The representation is equivalence and not an approximation, thus keeping the accuracy of the neural network exactly as is. We believe that this work provides better understanding of neural networks and paves the way to tackle their black-box nature. We share equivalent trees of some neural networks and show that besides providing interpretability, tree representation can also achieve some computational advantages for small networks. The analysis holds both for fully connected and convolutional networks, which may or may not also include skip connections and/or normalizations.”
“Diffusion models are auto-encoders”, Sander Dieleman, January 2022
“Denoising autoencoders are neural networks whose input is corrupted by noise, and they are tasked to predict the clean input, i.e. to remove the corruption. Doing well at this task requires learning about the distribution of the clean data. They have been very popular for representation learning, and in the early days of deep learning, they were also used for layer-wise pre-training of deep neural networks. It turns out that the neural network used in a diffusion model usually solves a very similar problem: given an input example corrupted by noise, it predicts some quantity associated with the data distribution. This can be the corresponding clean input (as in denoising autoencoders), the noise that was added, or something in between. All of these are equivalent in some sense when the corruption process is linear, i.e., the noise is additive: we can turn a model that predicts the noise into a model that predicts the clean input, simply by subtracting its prediction from the noisy input. In neural network parlance, we would be adding a residual connection from the input to the output.”
References: initial blog article: Diffusion models are autoencoders – More recent blog article: Perspectives on diffusion
Transformers are Graph Neural Networks, Chaitanya K. Joshi, June 2021
“Consider a sentence as a fully-connected graph, where each word is connected to every other word. Now, we can use a GNN to build features for each node (word) in the graph (sentence), which we can then perform NLP tasks with.
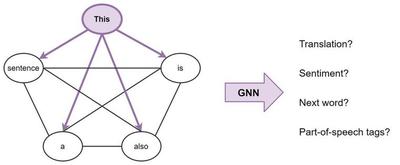
Broadly, this is what Transformers are doing: they are GNNs with multi-head attention as the neighbourhood aggregation function. Whereas standard GNNs aggregate features from their local neighbourhood nodes j ∈ N(i), Transformers for NLP treat the entire sentence S as the local neighbourhood, aggregating features from each word j ∈ S at each layer.”
References: blog article
“Gradient descent training for an infinite neural network can be described by kernel methods and Infinite neural networks evolve as linear models under gradient descent “, Arthur Jacob et Al., January 2018
“At initialization, artificial neural networks (ANNs) are equivalent to Gaussian processes in the infinite-width limit, thus connecting them to kernel methods. We prove that the evolution of an ANN during training can also be described by a kernel: during gradient descent on the parameters of an ANN, the network function fθ (which maps input vectors to output vectors) follows the kernel gradient of the functional cost (which is convex, in contrast to the parameter cost) w.r.t. a new kernel: the Neural Tangent Kernel (NTK). This kernel is central to describe the generalization features of ANNs. While the NTK is random at initialization and varies during training, in the infinite-width limit it converges to an explicit limiting kernel and it stays constant during training. This makes it possible to study the training of ANNs in function space instead of parameter space. Convergence of the training can then be related to the positive-definiteness of the limiting NTK. We prove the positive-definiteness of the limiting NTK when the data is supported on the sphere and the non-linearity is non-polynomial. We then focus on the setting of least-squares regression and show that in the infinite-width limit, the network function fθ follows a linear differential equation during training. The convergence is fastest along the largest kernel principal components of the input data with respect to the NTK, hence suggesting a theoretical motivation for early stopping. Finally we study the NTK numerically, observe its behavior for wide networks, and compare it to the infinite-width limit.”
References: Paper, my blog article on it.
Note: The picture above is Blake and Sungha.
Copyright © 2005-2023 by Serge-Paul Carrasco. All rights reserved.
Contact Us: asvinsider at gmail dot com.
Categories: Algorithms, Deep Learning, Machine Learning
